Before we begin, let me make some clarifications. A vector is represented by a letter which is often written as bold in text to distinguish it from scalars. When representing a vector with an arrow, the tail is defined to be the starting point of the vector, and the tip is defined to be the end point of the vector
Vectors are often defined as having separate, independent components. We showed that in two dimensions, every vector that exists can be described uniquely as a sum of the product of the basis vectors, which is the formal name for the unit vectors i-hat and j-hat, and uniquely determined constants c1,c2. This also is the case for three dimensional space, but three independent constant are required, c1,c2 and c3. The visual interpretation that follows is that every vector in three dimensional space therefore can be 'broken' down into vector components which are parallel to the x, y, and z axis.
.
Component by component: the physical meaning
This is a very useful concept in physics, as it allows us to independently consider what a particle which is acted on by a force experiences in the x,y and z direction. Then, we can take the vector sum and see what the net force on the object is, and use F=ma to figure out its net acceleration.
Another use in breaking forces down into component is to figure out the work done on an object. Suppose a particle is attached to a horizontal rail, which can be represented as the x-axis. After being acted on by a steady, constant force which makes a positive acute angle ϴ the horizontal, the particle accelerates and gets displaced by a certain amount. Force and displacement are both represented by vectors, so if we place the particle at the origin of our 2-D coordinate system, the force vector F and the displacement vector s (vectors are written in bold in text) will have their tail both rooted in the origin.
Now, if we break the force into components, there will be a vertical component of F pointing up and a horizontal component of F pointing to the right. Now, since there are other forces acting on the object, i.e its weight and the traction due to the rail, (but we assume no friction) we assume that all the vertical components cancel out and the only net force on the object is the horizontal component of F. Only the horizontal component of F does work on the object. Since Work=Force times distance, the way we calculate this is to simply take the magnitude of the horizontal component of F, which is by simple trig Fcos(ϴ) and the magnitude of the displacement vector s.

The Dot Product
This is such common practice that we give this process a name: it is called taking the dot product of two vectors.
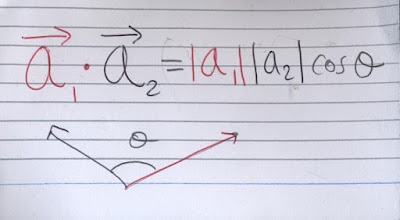
In general, the dot product of v and w is defined as the product of their magnitudes and the cosine of the angle in between. Note that the dot product takes in two vectors and outputs a regular number, a scalar. Since the magnitudes of v and w and cos ϴ are all numbers, we are free to change the order as we please. This implies an important property of the dot product: commutativity.

In general, the dot product of v and w is defined as the product of their magnitudes and the cosine of the angle in between. Note that the dot product takes in two vectors and outputs a regular number, a scalar. Since the magnitudes of v and w and cos ϴ are all numbers, we are free to change the order as we please. This implies an important property of the dot product: commutativity.
There are more important properties which is implied by the definition; the dot product is distributive; since the definition only involves the product of three scalars, it follows that the order shouldn't matter. Another important one comes from the trigonometric function involved: the dot product of two orthogonal (fancy word for perpendicular) vectors is always zero. A third property is that the dot product of a vector with itself is its magnitude squared, since the angle in between is 0.
Here is a less obvious property. In taking the dot product of v and w, suppose that I throw in a scalar in there. In other words, suppose that the vector v, let's say, can be written as a scaled version of a third vector, u. v=cu.
Using the definition, we end up with the dot product of v and w being |v||cu|cos (theta).
The cosine theta is no problem, but how do we deal with the second term, |cu|?
Well, using similar triangles, we can argue the following. Since the x and y component of u is multiplied by c to give the vector cu, the hypotenuse of a right triangle created by breaking u into its x and y components must also have its length scaled by c. But the length of the hypotenuse really is geometrically equivalent to the norm or magnitude of u, so the magnitude of cu must be c times the magnitude of u, or in other words, |cu|=c|u|.
Some more important properties involve the zero vector: a vector whose every component is zero. Following from the fact that the zero vector has zero magnitude, the dot product of a vector with the zero vector is always the number zero.
Below is a handwritten summary of a good number of dot product properties we have used, the list from which I took from the website <chortle.ccsu.edu/vectorlessons/vch07/vch07_8.html>.
An interesting duality: makes life alot easier!
I hope you agree with me in saying that this definition is pretty intuitive, and it fairly rigorous as well- except for the ambiguity of which angle we use (it doesn't really matter, but the angle less than pi radians is often chosen). However, it is a real pain to compute. It isn't even defined in three dimensions, let alone n dimensions! Furthermore, one has to compute the magnitude of the vector, and the direction! It is totally defined for more than two vectors, but it can end up being a real headache!
It turns out that this really neat duality exists between this physical representation of the dot product and a mathematical object that you have met before- matrices. Now, matrix multiplication isn't even defined technically for n by one with n by one vectors, but the process you take the dot product is very similar.
Therefore, to compute the dot product of two or more vectors, simply take the sum of the product of the corresponding components!

Another proof does exist for the dot product using the law of cosines, but I would at this point challenge the reader to derive this alternate proof.
CROSS PRODUCT
In elementary physics, we like to assign vectors associated to rotation. For example, the torque of an object is defined as the perpendicular component of force multiplied by distance from pivot point. Actually, this is incomplete, since we want to define torque as a vector. Why? To remove ambiguity. I could apply the same resultant force to the right of the pivot with the same angle, and in a different scenario, the same force to the left of the pivot with the same angle but get an opposite effect. Therefore, we define the torque vector in the latter case to point in the opposite direction as in the former case, albeit having the same magnitude.
We can imagine defining a vector r which represent the point at which we apply the force: starting at the pivot and ending at that mentioned point. Force F is already a vector. Because it is the vertical component that we care about, it will be the magnitude of the force times the magnitude of the displacement from pivot times the sine of the angle in between.
To complete this, we want to add direction. The cleanest way to do this is to define a unit vector which is orthogonal to both vectors in the plane, hence requiring the z axis. The direction is defined by the right hand rule: if the quickest way to get from the first vector to the second vector is to walk anti-clockwise, the normal unit vector will pop out of the page and towards you. If it is clockwise, then the normal unit vector will pop into the page and away from you.
Finally, putting it all together, we multiply the magnitude of the torque, given by |F||r|sin theta with the normal unit vector, so that we get a vector which points in the desired direction with desired magnitude.


Using this definition, we can immediately infer a property of the cross product of u and v, namely that it is anticommutative, or in other words, u×v = -(v×u).
I would say that this is fairly intuitive actually, because if F and r were to switch places, like in the example above, the direction you would have to walk from the first to the second vector would be opposite, and so the direction of the cross product vector would be also opposite. Since theta is the same, and since the magnitudes are unaffected, the magnitude would be the same for both vectors, but the minus sign simply reflects the fact that the two cross product vectors point in the opposite direction.
Just like in the dot product however, if I were to take the cross product of a vector cu, where c is a scalar, then: : (cu)×v=|cu||v|sinϴ=c|u||v|sin=c(u×v)
We can also deduce other properties of the cross product, for example it is distributive over a sum:
(u+v)×w=|u+v||w|sinϴ n=(|u||w|sinϴ +|v||w|sinϴ)n= (|u||w|sinϴn +|v||w|sinϴn)=u×w+v×w
which is seen before in the dot product.
Note that although it requiring three dimensions, this cross product definition doesn't give us a direct way to compute the cross product of three dimensional vectors. Let's derive it now, using the definition and basic properties.
First of all, we need to discuss how the three dimensional cartiesan coordinate system is orientated. The question is, there is a convention of which way the positive y axis and the positive x axis is orientated, but for the positive z axis, which way will it be orientated? Unsurprisingly, the z-axis is defined by the right hand rule; point your index finger in the direction of the increasing x axis, your middle finger in the direction of the increasing y axis, and your thumb will point in the direction of increasing z axis. Let's rephrase this definition of the cross product: the x unit vector i-hat cross y unit vector j-hat must be the z unit vector k-hat.

Let's now elaborate and find more rules. We can milk j i -k using anticommutativity. Here are a list of equations linking the basis vectors using the cross product:


 Expanding out, and simplifying using the cross products of the unit vectors discussed earlier, we arrive at the final formula.
Expanding out, and simplifying using the cross products of the unit vectors discussed earlier, we arrive at the final formula.
Now, it turns out that this expression is exactly the same as taking the determinant of a three by three matrix with the components of the a and b unit vector, and the i,j and k-hat unit vectors all arranged in a praticular manner.
If you are unfamiliar of taking the determinant of a three by three matrix, or what a matrix even is, I will for now provide you with a superficial explanation. A matrix is simply an array of numbers, arranged into rows and columns. It is, if you like, a table of quantities. A matrix can have as many rows or column as one likes, and it does not even have to be finite!
For special types of matrices, called square matrices, which have the same number of rows and columns, there is a single number which is quite useful to know, called a determinant.
To find a determinant of a 2 by 2 matrix, take the difference of the product of "northwest-southeast" diagonal number and the product of the "northeast-southwest" diagonal.
Finding a determinant of a higher dimension matrix is somewhat of an iterative process. The process for a 3 by 3 matrix is described below:

And then, if you list the unit vectors on the top row, and then the components of the first vector in the second row, and the components of the second vector in the third row in a 3 by 3 matrix, the determinant turns out to be simply a cross b.
Here is a less obvious property. In taking the dot product of v and w, suppose that I throw in a scalar in there. In other words, suppose that the vector v, let's say, can be written as a scaled version of a third vector, u. v=cu.
Using the definition, we end up with the dot product of v and w being |v||cu|cos (theta).
The cosine theta is no problem, but how do we deal with the second term, |cu|?
Well, using similar triangles, we can argue the following. Since the x and y component of u is multiplied by c to give the vector cu, the hypotenuse of a right triangle created by breaking u into its x and y components must also have its length scaled by c. But the length of the hypotenuse really is geometrically equivalent to the norm or magnitude of u, so the magnitude of cu must be c times the magnitude of u, or in other words, |cu|=c|u|.
Some more important properties involve the zero vector: a vector whose every component is zero. Following from the fact that the zero vector has zero magnitude, the dot product of a vector with the zero vector is always the number zero.
Below is a handwritten summary of a good number of dot product properties we have used, the list from which I took from the website <chortle.ccsu.edu/vectorlessons/vch07/vch07_8.html>.
An interesting duality: makes life alot easier!
I hope you agree with me in saying that this definition is pretty intuitive, and it fairly rigorous as well- except for the ambiguity of which angle we use (it doesn't really matter, but the angle less than pi radians is often chosen). However, it is a real pain to compute. It isn't even defined in three dimensions, let alone n dimensions! Furthermore, one has to compute the magnitude of the vector, and the direction! It is totally defined for more than two vectors, but it can end up being a real headache!
It turns out that this really neat duality exists between this physical representation of the dot product and a mathematical object that you have met before- matrices. Now, matrix multiplication isn't even defined technically for n by one with n by one vectors, but the process you take the dot product is very similar.
Therefore, to compute the dot product of two or more vectors, simply take the sum of the product of the corresponding components!

Another proof does exist for the dot product using the law of cosines, but I would at this point challenge the reader to derive this alternate proof.
CROSS PRODUCT
In elementary physics, we like to assign vectors associated to rotation. For example, the torque of an object is defined as the perpendicular component of force multiplied by distance from pivot point. Actually, this is incomplete, since we want to define torque as a vector. Why? To remove ambiguity. I could apply the same resultant force to the right of the pivot with the same angle, and in a different scenario, the same force to the left of the pivot with the same angle but get an opposite effect. Therefore, we define the torque vector in the latter case to point in the opposite direction as in the former case, albeit having the same magnitude.
We can imagine defining a vector r which represent the point at which we apply the force: starting at the pivot and ending at that mentioned point. Force F is already a vector. Because it is the vertical component that we care about, it will be the magnitude of the force times the magnitude of the displacement from pivot times the sine of the angle in between.
To complete this, we want to add direction. The cleanest way to do this is to define a unit vector which is orthogonal to both vectors in the plane, hence requiring the z axis. The direction is defined by the right hand rule: if the quickest way to get from the first vector to the second vector is to walk anti-clockwise, the normal unit vector will pop out of the page and towards you. If it is clockwise, then the normal unit vector will pop into the page and away from you.
Finally, putting it all together, we multiply the magnitude of the torque, given by |F||r|sin theta with the normal unit vector, so that we get a vector which points in the desired direction with desired magnitude.


Using this definition, we can immediately infer a property of the cross product of u and v, namely that it is anticommutative, or in other words, u×v = -(v×u).
I would say that this is fairly intuitive actually, because if F and r were to switch places, like in the example above, the direction you would have to walk from the first to the second vector would be opposite, and so the direction of the cross product vector would be also opposite. Since theta is the same, and since the magnitudes are unaffected, the magnitude would be the same for both vectors, but the minus sign simply reflects the fact that the two cross product vectors point in the opposite direction.
Just like in the dot product however, if I were to take the cross product of a vector cu, where c is a scalar, then: : (cu)×v=|cu||v|sinϴ=c|u||v|sin=c(u×v)
We can also deduce other properties of the cross product, for example it is distributive over a sum:
(u+v)×w=|u+v||w|sinϴ n=(|u||w|sinϴ +|v||w|sinϴ)n= (|u||w|sinϴn +|v||w|sinϴn)=u×w+v×w
which is seen before in the dot product.
Note that although it requiring three dimensions, this cross product definition doesn't give us a direct way to compute the cross product of three dimensional vectors. Let's derive it now, using the definition and basic properties.
First of all, we need to discuss how the three dimensional cartiesan coordinate system is orientated. The question is, there is a convention of which way the positive y axis and the positive x axis is orientated, but for the positive z axis, which way will it be orientated? Unsurprisingly, the z-axis is defined by the right hand rule; point your index finger in the direction of the increasing x axis, your middle finger in the direction of the increasing y axis, and your thumb will point in the direction of increasing z axis. Let's rephrase this definition of the cross product: the x unit vector i-hat cross y unit vector j-hat must be the z unit vector k-hat.

Let's now elaborate and find more rules. We can milk j i -k using anticommutativity. Here are a list of equations linking the basis vectors using the cross product:

Now we are ready to find a general formula that gives us a cross b in terms of the components of each vector.


Now, it turns out that this expression is exactly the same as taking the determinant of a three by three matrix with the components of the a and b unit vector, and the i,j and k-hat unit vectors all arranged in a praticular manner.
If you are unfamiliar of taking the determinant of a three by three matrix, or what a matrix even is, I will for now provide you with a superficial explanation. A matrix is simply an array of numbers, arranged into rows and columns. It is, if you like, a table of quantities. A matrix can have as many rows or column as one likes, and it does not even have to be finite!
For special types of matrices, called square matrices, which have the same number of rows and columns, there is a single number which is quite useful to know, called a determinant.
To find a determinant of a 2 by 2 matrix, take the difference of the product of "northwest-southeast" diagonal number and the product of the "northeast-southwest" diagonal.
Finding a determinant of a higher dimension matrix is somewhat of an iterative process. The process for a 3 by 3 matrix is described below:






























{kind=link}