Friday, 19 August 2016
Update on EPQ research
Primarily, I have dedicated to this blog to my main passion of communicating ideas in mathematics to readers, and also venturing into the technical details. In this blog post, I aim to do something slightly different: I would like to explain what my actual EPQ is, and what stage I currently happen to be in.
My EPQ is based on Maxwell's equations, and I have been doing some background research for the past month. I believe I underestimated the depth that I end up going into the mathematics behind it, and currently haven't explored the physics application of all of this research. Furthermore, I have found myself working behind schedule, even though I have been keeping at this consistently every day. I have yet to refine my topic idea in Maxwell's equations; it is still a work in progress, despite it being into mid August.
I aim to keep it simple, and discuss in my ultimate dissertation what the importance of maxwell's equations were, and why it is a corner stone in physics. It is the first successful attempt at unifying electricity and magnetism, and the fundamental postulate in physics, that there are quantities which remain invariant under what are called Lorentz Transformations was first implied by this. Namely, the speed of light as a universal constant, which is the heart and veins of relativity, fell straight out of these equations.
I believe I owe a quick explanation to the reader what a Lorentz Transformation is. Simply put, it is the mathematical process of switching between two non-accelerating, called inertial, reference frames, which move with a relative constant velocity to each other. As an example, if I compared what flow of time and what measurements of distance an observer moving in a space ship at half the speed of light (with no acceleration) as opposed to an observer on earth would experience, I would have to perform a Lorentz Transformation. At either case, the guiding principal behind the mathematics is the fact that some quantities are the same universally, i.e. do not vary, or in other words, remain invariant, such as the speed of light and the path between spacetime, under these Lorentz transformations. I shall end this here, lest I digress into relativity.
My plan from this point on is to pick up more speed in my research. I have a five day vacation planned soon, and then the year thirteen begins with all the UCAS application process, so I really should aim to be done completely in terms of background research by then.
In terms of my background research, I have used the following resources: Khan Academy, Yale lectures by Dr. Ravi Shanker, My Young Freedman University Physics textbook and finally a Vector Calculus book by Springer Undergraduate Mathematics Series, written by R.C Matthews.
Let me delve into the concepts which I covered and feel fairly confident in: Understanding multi variable functions, differentiation in multivariable calculus (the partial derivative, the gradient, the directional derivative, curl, divergence, the vector valued function and the formal definition, multivariable chain rule), topics borrowed from linear algebra (span, vectors, cross and dot product, proof of these formulae), integration in multivariable calculus (double, triple integral, surface integrals, line integrals, conservative vector fields, intuition, derivation and intuition of the fundamental theorem of line integrals (which is a cousin to the fundamental theorem(s) of calculus), and flux in 2D) In physics, I have studied mainly from the Yale lectures and the uni physics textbook on the following topics, electrostatics, electric fields, symmetry arguments, and Gauss' law, which is the first of maxwell's equations. Got plenty of more content to cover, however.
Monday, 15 August 2016
Basic intro to vectors, addition and multiplication by a scalar.
Thinking about vectors
Vectors, for the purposes of elementary physics, is a quantity which has two separate pieces of information embedded in it: magnitude (sometimes called the norm) and direction. At least this is the interpretation which we will use. Vectors are often depicted as arrows, where the arrow's length typically corresponds with the magnitude, and its orientation corresponds with direction. Vectors can be depicted in one, two, or three dimensions, and can even live in n dimensions greater than three, but then it becomes impossible to visualise as a simple arrow in space. For the purposes of using vectors for physical phenomena such as electromagnetism, we shall constrain ourselves to no more than three dimensional space.
How is magnitude and direction defined?
To describe a vector fully the direction and magnitude has to be specified. There are many ways of doing this, and they are all correct so long as there is absolutely no ambiguity over what the magnitude and direction of the vector being described. The methods of describing it will be described later on in this article.
A Useful property of vectors
Due to the way that we have defined a vector as being a quantity of only magnitude and direction, a useful property is implied when we imagine vectors as arrows in space.
I like to think of a vector as a set of instructions for movement: "Walk x metres in this direction." Then, imagine asking it, "Ok, where do I start from?" Then the vector will reply: "I don't care."
The vector only gives information about the direction and magnitude of movement. Hence, it doesn't matter where the initial point is, and by that logic that implies that two vectors which have the same magnitude and direction but placed at the point (2,2) and the other placed at (-1000,23.4533234) are equivalent.
Since it doesn't matter where you root your vector, in mathematics we tend to place the tail at the origin because it makes calculations simple.
Two elementary operations on vectors
There are two fundamental operations which one can perform on a vector. It is vector addition, and scalar multiplication. There are more of course, but these two are the springboard.
Vector addition
Suppose that we take a really simple space where we can perform our vector operations in, the one-dimensional number line. And suppose, vector v tells you to move 6 meters to the right, and vector w tells you to move 3 meters to the left. Now, imagine that we were interested in the combined effect of v and w. What does doing v first and then doing w second effectively amount to? In other words, what does v+w look like?
We can display v and w as two separate arrows. Here they are:
 |
| vector v |
 |
| vector w |
Now, try to imagine a graphical way to represent this combined effect that v and w has.
Hint: use the previously discussed fact that you can slide any of the two vectors along anywhere that you desire along the number line without changing its identity.
It turns out that if we take w and place the tail of the arrow onto the tip of v, then the tip of w lies exactly on top of the answer. Then, we can even further extend this idea, and define a new vector v+w to start at the point where we started, and end at the point where we ended. This new vector tells you straight away where you will end up without having to do v and w seperately.
 |
| "Adding" the vectors |
 |
| v+w |
Now, importantly, this is the geometric equivalent of saying 3=(5)+(-2). And, just like how we can equivalently say that 3=(-2)+(5), it is the case that v+w=w+v.
This can also be done in two dimensions and three dimensions. As a general rule, to find v+w, bring the tail of w so it touches the tip of v, and drawing an arrow from the tail of v to the tip of the newly placed w gives you the vector v+w. This can be done in the opposite order too.
 |
| Vector v and w rooted at the origin |
 |
| Sliding or "translating" one of the vectors is allowed |
 |
| The vector v+w starts at what I like to call the "free ends": the tail of the vector that wasn't moved, and the tip of the vector that was moved. |
{kind=link}
Scalar multiplication
We used the idea of addition from arithmetic to explain vector addition, and show that they are fundamentally the same idea. What about multiplication?
Well, suppose that we take vector v which tells you how far you have walked along the number line. Then, what would the vector 2v look like? That is easy. If you walked twice as far, the arrow representing the vector will be twice as long. In general, the magnitude of the vector cv is simply c times the magnitude of v.
The Cartesian Starter Pack: Basis Vectors.
Now, returning to the xy plane, there really are two vectors that you will ever need. A vector, which I will from now on use interchangeably with "arrow" which points horizontally and is of magnitude one, and another vector which points vertically and is of magnitude one as well.
We give these vectors names: i-hat for the former (which I will denote as simply i, don't confuse it with i from complex numbers), and j-hat for the latter (which I will also denote as j).

Take the i-hat unit vector, and scale it to the vector xi. Next, take the j-hat unit vector, and scale it to yj.
 |
| I used x0 and y0 instead of just saying x and y to emphasise that these are arbitrary but particular points on the plane. There is no effective difference though, that is my choice of notation. |
Then, if you bring the tail of the vector yj to the tip of xi, it will touch the point (x,y). But this is vector addition, so this means that the vector v really is the same thing as saying xi+yj.

 That helpfully breaks our vector up into horizontal and vertical components, which is a very common practice in physics and mathematics- practice doing this!
That helpfully breaks our vector up into horizontal and vertical components, which is a very common practice in physics and mathematics- practice doing this!
Hence, a vector which is rooted at the origin and represents a point (x,y) is given by v=xi+yj.
This vector describes a unique position on the x,y plane, so we give it a special name: the position vector, which you met in my previous blog.
This can be extended to three dimensions, where the basis vectors are i,j, and k for the x,y, and z axis respectively.
Column vector notation
Another popular way of denoting a vector v=xi+yj is also by writing the x and y components in a column vector form, shown blow.
 |
| V can be therefore written in terms of the i and j hat unit vectors, or in column vector notation. A vector which is rooted in the origin is often called a position vector, and the letter used instead of v often is r. |
Algebraic and Analytical vector addition and vector-scalar multiplication
Let's now try to add two vectors v and w with x components x1 and x2 respectively, and y components y1 and y2 respectively. From combining like terms, we can algebraically prove that the sum of two vectors is the same as the sum of the corresponding components:

Similarly, we can also show that the product of a vector and a scalar c is equivalent to the product of the x-component and c, the y-component and c, and so on:

In column vector notation form:

Sunday, 7 August 2016
Using Khan Academy to master multivariable calculus
Survey of the Fundamental Concepts in Multivariable Calculus.
As I build the foundational work for my EPQ research, I have extensively used the amazing educational website khan academy to master fundamental mathematical tools and concepts defined in multivariable calculus. At the time of the last edit, the 6th of August, I have finished the sub-courses on visualising multivariable functions, differentiating multivariable functions, and now I am studying integrating multivariable functions. I have taught myself the essence of line integrals, and now I am studying two dimensional flux.
Let the Maths Begin!: Revisiting Functions, Vectors, and Parametrisation
Scalar vs. Vector Valued Functions



Scalar vs. Vector Valued Functions
To begin, I would like to introduce another type of function that you may not be used to yet: the vector-valued function.
A scalar valued function is essentially what is meant in everyday maths life when one says: "function." It is something that takes in a scalar and outputs a scalar.
To get a more concrete idea of what a scalar function is, and to revisit the underlying intuition, it is useful to think of a scalar valued function like this: feed it a point on a number line (for a single-variable scalar function,) or on the xy plane (for a two variable scalar function) or in space (for a three-variable scalar function) or in n dimensions, and it will return another single scalar value: a number.
In other words, there could be n dimensions in the input space, with n different variables, such as x,y,z, etc. but only one scalar value is returned in any case. What we often consider in single variable calculus is an input space being a number line (hence it being a one-dimensional input space) and the output being a number line, too. In this case, the dimensions of what goes in matches the dimensions of what goes out.
To get a more concrete idea of what a scalar function is, and to revisit the underlying intuition, it is useful to think of a scalar valued function like this: feed it a point on a number line (for a single-variable scalar function,) or on the xy plane (for a two variable scalar function) or in space (for a three-variable scalar function) or in n dimensions, and it will return another single scalar value: a number.
In other words, there could be n dimensions in the input space, with n different variables, such as x,y,z, etc. but only one scalar value is returned in any case. What we often consider in single variable calculus is an input space being a number line (hence it being a one-dimensional input space) and the output being a number line, too. In this case, the dimensions of what goes in matches the dimensions of what goes out.
(Note: in my diagrams, I will often denote green as the input space and red as the output space for the ease of the reader).
 |
| Figure 1 Two times two equals four: This is the typical visualisation of functions actively mapping numbers from set A to set B. Instead of numbers just existing as a list in A and B, it is more convinient to depict the numbers sitting on a number line, since the domain and range here are continuous. Here, I have chosen the function f(x)=2x as an example, and a point x=2 gets mapped to f(2)=4. |
 |
| Figure 2 This is a more common way to visualise functions: I have made the x and f(x) number lines perpendicular to one another, in effect merging the input and the output space into a two dimesnional plane. I chose the x to be on the horizontal axis by convention. Here, I visualise this line, the graph of f(x)=2x as 'guiding' the input point 2 to the point 4 on the f(x) axis. A less complicated way of visualising this is to define the vertical axis as the y axis, another variable separate to x. The points (x,y) that satisfy the equation y=f(x) form a line, or a curve, which is called the graph of the function. |
To make what we mean as a multivariable scalar function more concrete, here the same idea, extended to a two dimensional space onto an output number line. Take note that regardless how many dimensions I choose my input to be, the output will always be a one-dimensional input. Here is a visualisation:

The common and convinient way here is to merge the input and output space yet again, and so we have two dimensions from the input and one dimension from the output, giving us a graph which requires three dimensions, an x and y axis and a z axis which is a function of x and y. The resulting graph will be a two dimensional surface, like the one depicted below. Note that I have put the graph in a box, but that has nothing to do with the actual function. It just nicely frames the graph.

Observe below how the same point we probed last time, (π/6,π,3) gets mapped to the point z=13/4.
Consequently, when we merge the two spaces together, (π/6,π/3,13/4) lies directly above
(π/6,π/3,0).
The z value corresponds to the height of the graph, just like in single variable function.


Vector Valued Functions
I would now like to introduce the idea of a vector valued function. It is quite a simple idea: the function inputs a scalar (or a vector) but outputs strictly a vector. The first instance when one is introduced to this idea is when two mathematical tools are combined: parametric equations and the position vector.
Since each point that lies on the line is a function of t, it is given by the coordinates ( x(t), y(t) ). Then, x and y are defined separately. For example, x(t)=rcos(t) and y(t)=rsin(t) trace out a circle of radius r. Very importantly, however, we tend to restrict the domain of t; there are several reasons for this. First, we tend to want to end up with a curve which is finite, that has a definite start and end point. Secondly, t usually represents time, and the curve "driven" by the t on the xy plane is defined from t=0 onward. In the example of the circle above, the domain on t is 0 ≤ t ≤ 2π. Of course, the domain is arbitrary. If we wanted to trace out a semicircle, then 0 ≤ t ≤ π is the appropriate domain. Note: we only work in radians in 'higher' mathematics, and I will never switch to degrees unless I state otherwise.
Since I glossed over the details here, I will aim to write a separate article on parametric equations, since it is very important indeed.
In two dimensions, a point (x,y) would be represented by a vector whose tail lies on the origin (0,0) and whose tip extends to the point (x,y). Note: x,y can be any point, even (0,0) itself, in which case the vector would have zero length.
 This special vector is called the "position vector." The two separate pieces of information we need in order to deduce the point which the vector is trying to represent is the length and direction. Length is also referred to as the magnitude of a vector, and in higher mathematics, the magnitude of a vector is called its "norm", and in particular, its "Euclidean Norm". I will henceforth call the length of a vector its norm. The common notation for this is to put two bars around the vector: ||v||.
This special vector is called the "position vector." The two separate pieces of information we need in order to deduce the point which the vector is trying to represent is the length and direction. Length is also referred to as the magnitude of a vector, and in higher mathematics, the magnitude of a vector is called its "norm", and in particular, its "Euclidean Norm". I will henceforth call the length of a vector its norm. The common notation for this is to put two bars around the vector: ||v||.
In one dimension, the norm of a vector is identical to taking the modulus of the difference of the end value of x and the start value of x. In other words, if you want to find the norm of the vector in one dimensions, simply put the start point on zero, and take the modulus of the end point x. This is the actual value of the vector. In the case above, v=-2. The norm, or length of v is identical to the modulus to the vector, and the direction can be deduced by looking at its sign.
In two dimensions, finding the norm is less intuitive: it is calculated by taking the positive square root of the sum of the squares of the x and y component of the vector, by the pythagorean theorem, and in three dimensions, the square root of the sum of the squares of the x, y and z components, and so on into n dimensions. In two dimensions, we give the direction of the vector by the angle it makes with the positive x-axis. In three dimensions, we need three separate angles, the angles it makes with each axis, and this carries on to n dimensions.
Now, there is one last thing I want to note: because the two key pieces of information embedded in the blue print of the vectors is length and direction, the starting points and end points do not matter. Hence, you can argue that the vector representing the point (2,3) could start arbitrarily any where. However, to make life easier, we tend to attach the tail of the position vectors to the origin, so the tip touches the point that we are interested in. Therefore, all points in our n-dimensional space can be uniquely represented by one and only one vector.
As a quick review, there are two very important operations that can be done to vectors which I will assume that you are confident in. There is addition of vectors, which is visually found through the tip-to tail procedure, and the scalar multiplication of vectors: multiplying a vector by a number, called a "scalar," never affects its direction, but will multiply the norm by the scalar. Finally, we define a vector which is of length one along the x axis the i-hat unit vector, and a vector which is also of length one but point up the y-axis the j-hat unit vector. These vectors follow all the rules of addition and scalar multiplication just like any other vector.
Let me illustrate first how to define a position vector for the point (2,3) on the xy plane. Consider two separate vectors, on which is pointing to the right and has 2 units of length, and the other pointing up and has 3 units of length. The vector pointing along the horizontal can be represented by a unit length vector i-hat, but scaled up by 2. Similarly, the vector pointing along the y-axis can be represented by a j-hat unit vector, but scaled up by a factor of 3. Again, where we place these vectors is arbitrary, so I will place them such that it will lie tip to tail. Ah! But that is vector addition, so really the position vector for (2,3) is identical to saying the sum of the horizontal and vertical vectors. Therefore, the position vector for (2,3) is



You will notice that there is an exact correspondence here: the position vector for a given (x,y) is simply the the x-value, a scalar, multiplied by the i-unit vector, and the y-value multiplied by the j-unit vector. Therefore, for a position vector centred at the origin, the point (x,y) on the plane is represented by a vector r=xi+yj.
We already established that for a given value of t (that lies in its domain) the parametric equations will output a coordinate ( x(t), y(t) ). For example, the point along the path at t=0 will be given by ( x(0), y(0) ). Now, the point on the curve at t=0 will be a point on the xy plane, and as I have shown earlier, this can be represented by a position vector r=x(0)i+y(0)j.
By that reasoning, we can define a separate position vector for t=1, which will then be r=x(1)i+y(1)j and t=2, which would be, you guessed it, r=x(2)i+y(2)j, and so on and all the infinite values of t in between, and for all the values of t for which this parametric curve is defined for.
Now, you can immediately point out that if you give me an arbitrary value for t, I will give you a position vector. Well, that is suspiciously similar to the idea of a function, but with the only difference that the input is a scalar, a value for t, and the output is a vector. And that, ladies and gentleman, is an example of a vector-valued function, namely, a position vector valued function.
In this case, as illustrated below, a point from a 2-dimensional input space gets mapped to a vector in the output space. As an example, observe how the point (2,3) gets mapped to the vector 2i+3j, according to the way I have defined the function.
Now, since the vector does not care where I place it along the xy plane, I can bring it from the origin and make the start point coincide with the point that I originally inputted into my function: (2,3). In a sense, I am merging the input and outputs spaces together, just like what you do when you graph regular single-variable scalar functions or even 2-variable scalar functions.
In theory, I can perform this to all the points on the xy plane and its output vectors, but it will take me quite a bit of time considering that there are an infinite amount of them! Therefore, I choose to display a subset of all the vectors that do exist. I used the website https://kevinmehall.net to graph the vector field in full f(x,y)=xi+yj.

Vector fields then are super useful in physics as they can represent physical quantities. If you imagine fluid particle flowing through space, a vector associated to each point can very succinctly describe the velocity that a particular particle passing through that point would feel. Or, we can construct a vector field that would describe the force a positive test charge would feel at a given point in space due to another positive charge sitting at the origin of our coordinate system.
And now we are developing ideas that will be exceptionally relevant and useful in our discussion of electricity and magnetism, particularly maxwell's equations. However, we shall now venture into the "calculus" of multivariable calculus. That shall be the topic of the next blog post.
Parametric Equations
Parametrisation in the xy plane occurs when a parameter, a fancy word for a variable that does not have its own axis (unlike x and y), which is typically denoted by the letter t, is used to define points that lie on a path along the cartesian plane. The path defined by the curve is made up of all points (x,y) such that x and y are independent functions of t. An example of a use of this construct in physics is that if we observe that a particle travelling in two dimensions whose x and y coordinates can be defined as a function of time separately, then using parametrisation we can graph its journey given a time frame that we choose.Since each point that lies on the line is a function of t, it is given by the coordinates ( x(t), y(t) ). Then, x and y are defined separately. For example, x(t)=rcos(t) and y(t)=rsin(t) trace out a circle of radius r. Very importantly, however, we tend to restrict the domain of t; there are several reasons for this. First, we tend to want to end up with a curve which is finite, that has a definite start and end point. Secondly, t usually represents time, and the curve "driven" by the t on the xy plane is defined from t=0 onward. In the example of the circle above, the domain on t is 0 ≤ t ≤ 2π. Of course, the domain is arbitrary. If we wanted to trace out a semicircle, then 0 ≤ t ≤ π is the appropriate domain. Note: we only work in radians in 'higher' mathematics, and I will never switch to degrees unless I state otherwise.
Since I glossed over the details here, I will aim to write a separate article on parametric equations, since it is very important indeed.
Position Vectors
Now, as we progress in our study, we take a nuanced approach at parametric curves. First, I must explain that every point in space can be represented by a vector. This is the case for any n-dimensions of spa choose. For example, in one dimension, a point on the number line can be represented by a vector whose start point, its tail, sits at zero and whose end point, or tip, lies on the given point on the number line. The vector will have a length and a direction, the length being the distance travelled along the vector, and the direction in this case being left or right.In two dimensions, a point (x,y) would be represented by a vector whose tail lies on the origin (0,0) and whose tip extends to the point (x,y). Note: x,y can be any point, even (0,0) itself, in which case the vector would have zero length.
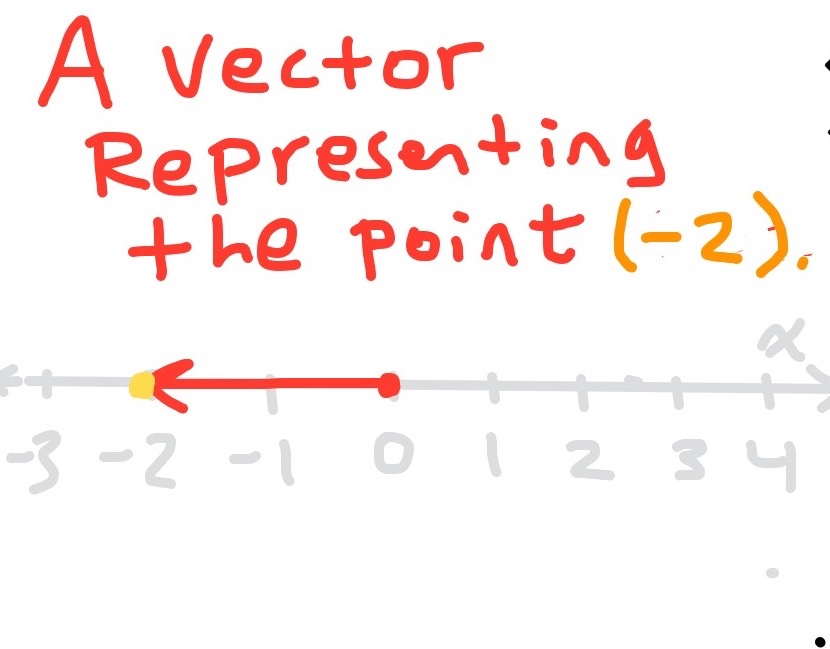
In one dimension, the norm of a vector is identical to taking the modulus of the difference of the end value of x and the start value of x. In other words, if you want to find the norm of the vector in one dimensions, simply put the start point on zero, and take the modulus of the end point x. This is the actual value of the vector. In the case above, v=-2. The norm, or length of v is identical to the modulus to the vector, and the direction can be deduced by looking at its sign.
In two dimensions, finding the norm is less intuitive: it is calculated by taking the positive square root of the sum of the squares of the x and y component of the vector, by the pythagorean theorem, and in three dimensions, the square root of the sum of the squares of the x, y and z components, and so on into n dimensions. In two dimensions, we give the direction of the vector by the angle it makes with the positive x-axis. In three dimensions, we need three separate angles, the angles it makes with each axis, and this carries on to n dimensions.
Now, there is one last thing I want to note: because the two key pieces of information embedded in the blue print of the vectors is length and direction, the starting points and end points do not matter. Hence, you can argue that the vector representing the point (2,3) could start arbitrarily any where. However, to make life easier, we tend to attach the tail of the position vectors to the origin, so the tip touches the point that we are interested in. Therefore, all points in our n-dimensional space can be uniquely represented by one and only one vector.
As a quick review, there are two very important operations that can be done to vectors which I will assume that you are confident in. There is addition of vectors, which is visually found through the tip-to tail procedure, and the scalar multiplication of vectors: multiplying a vector by a number, called a "scalar," never affects its direction, but will multiply the norm by the scalar. Finally, we define a vector which is of length one along the x axis the i-hat unit vector, and a vector which is also of length one but point up the y-axis the j-hat unit vector. These vectors follow all the rules of addition and scalar multiplication just like any other vector.
Let me illustrate first how to define a position vector for the point (2,3) on the xy plane. Consider two separate vectors, on which is pointing to the right and has 2 units of length, and the other pointing up and has 3 units of length. The vector pointing along the horizontal can be represented by a unit length vector i-hat, but scaled up by 2. Similarly, the vector pointing along the y-axis can be represented by a j-hat unit vector, but scaled up by a factor of 3. Again, where we place these vectors is arbitrary, so I will place them such that it will lie tip to tail. Ah! But that is vector addition, so really the position vector for (2,3) is identical to saying the sum of the horizontal and vertical vectors. Therefore, the position vector for (2,3) is



You will notice that there is an exact correspondence here: the position vector for a given (x,y) is simply the the x-value, a scalar, multiplied by the i-unit vector, and the y-value multiplied by the j-unit vector. Therefore, for a position vector centred at the origin, the point (x,y) on the plane is represented by a vector r=xi+yj.
We already established that for a given value of t (that lies in its domain) the parametric equations will output a coordinate ( x(t), y(t) ). For example, the point along the path at t=0 will be given by ( x(0), y(0) ). Now, the point on the curve at t=0 will be a point on the xy plane, and as I have shown earlier, this can be represented by a position vector r=x(0)i+y(0)j.
By that reasoning, we can define a separate position vector for t=1, which will then be r=x(1)i+y(1)j and t=2, which would be, you guessed it, r=x(2)i+y(2)j, and so on and all the infinite values of t in between, and for all the values of t for which this parametric curve is defined for.
Now, you can immediately point out that if you give me an arbitrary value for t, I will give you a position vector. Well, that is suspiciously similar to the idea of a function, but with the only difference that the input is a scalar, a value for t, and the output is a vector. And that, ladies and gentleman, is an example of a vector-valued function, namely, a position vector valued function.
 |
| To represent the point (x(t),y(t)), we can define a position vector whose tail lies on the origin, and whose x and y components are given by the above formula. |
 |
| Visualisation of a position vector function for any t in the closed interval [t0,t1]. |
Vector Fields
Defining a position vector valued function turns out to be extremely useful for future use. In addition to this position vector valued function, other vector valued functions can be defined. For example, one could define a vector valued function in the xy plane which is not necessarily parameterised, but depends on x and y. In other words, instead of it being you give me a t and I give you a vector, we could also define a vector such that you give me a point on the plane or in space, and I give you a vector. Note, the vector is two dimensional, too. This vector is often visualised as being attached to the particular input point. This ends up being very very important by creating an infinite amount of vectors for each point on the plane, or in space, or in n dimensions, and can describe, for example, the force a particle would feel at that point. Whenever we have the same number of dimensions in the input and output, we can visualise the vector-valued function as a vector "field."In this case, as illustrated below, a point from a 2-dimensional input space gets mapped to a vector in the output space. As an example, observe how the point (2,3) gets mapped to the vector 2i+3j, according to the way I have defined the function.
 |
| The point (2,3) gets mapped onto the vector 2i+3j. The vector, by convention, not by fundamental mathematical laws, is centred at the origin. |
Now, since the vector does not care where I place it along the xy plane, I can bring it from the origin and make the start point coincide with the point that I originally inputted into my function: (2,3). In a sense, I am merging the input and outputs spaces together, just like what you do when you graph regular single-variable scalar functions or even 2-variable scalar functions.
| In just the same way I am perfectly allowed to chose to place my vector in the origin, I can place it starting from any point I want. In this case, so we can see |
 |
| Here, one can clearly see that the input, the green point, and the output, the red vector has been merged together onto a single xy plane. |
In theory, I can perform this to all the points on the xy plane and its output vectors, but it will take me quite a bit of time considering that there are an infinite amount of them! Therefore, I choose to display a subset of all the vectors that do exist. I used the website https://kevinmehall.net to graph the vector field in full f(x,y)=xi+yj.

Vector fields then are super useful in physics as they can represent physical quantities. If you imagine fluid particle flowing through space, a vector associated to each point can very succinctly describe the velocity that a particular particle passing through that point would feel. Or, we can construct a vector field that would describe the force a positive test charge would feel at a given point in space due to another positive charge sitting at the origin of our coordinate system.
And now we are developing ideas that will be exceptionally relevant and useful in our discussion of electricity and magnetism, particularly maxwell's equations. However, we shall now venture into the "calculus" of multivariable calculus. That shall be the topic of the next blog post.
Subscribe to:
Comments (Atom)